本文总结了论文JWE:Joint Embeddings of Chinese Words, Characters, and Fine-grained Subcharacter Components中的核心思想。
导语
论文《Joint Embeddings of Chinese Words, Characters, and Fine-grained Subcharacter Components》是香港科技大学2017年在EMNLP发表的,同样是在词向量生成部分进行了改进,引入了人工总结的“字件信息”,提升了词向量的质量。
模型
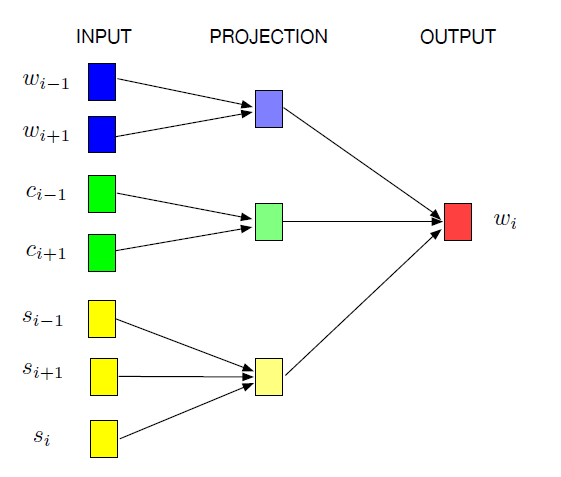
根据人工总结的“字件”,将汉字拆成一个一个的小模块,把词、汉字和字件一起联合学习词向量。其中$wi$是目标词,$w{i-1}$是目标词左边的词,$w{i+1}$是目标词右边的词;$c{i-1}$是目标词左边的词中的单字,$c{i+1}$是目标词右边的词中的单字;$s{i-1}$是目标词左边的词拆分的字件,$s_{i+1}$是目标词右边的词拆分的字件,$s_i$是目标词的字件;
模型的目标是最大化以下对数似然:
其中,$h{i_1}$,$h{i2}$,$h{i_3}$分别为上下文单词、单字、组件的组合。
在以上3个公式中,$v{w_i}$,$v{ci}$,$v{si}$分别为上下文、单字、字件的“输入向量”,$\hat{v}{wj}$是“输出向量”;$h{i1}$为上下文“输入向量”的均值,同理,$h{i2}$为上下文单字“输入向量”的均值,$h{i_3}$为上下文字件“输入向量”的均值。
给定语料$D$,模型的目标是最大化:
实验
文章在word similarity evaluation和word analogy tasks两个任务上对比JWE与之前词向量模型。
发现在word analogy tasks任务上取得了显著提高。