本文总结了神经网络在文本分类方面的一些应用,其中多篇论文被广泛引用。如果有最新的相关研究会及时更新。
文章将按照这些论文提出年份展开介绍,发展历史如下图所示: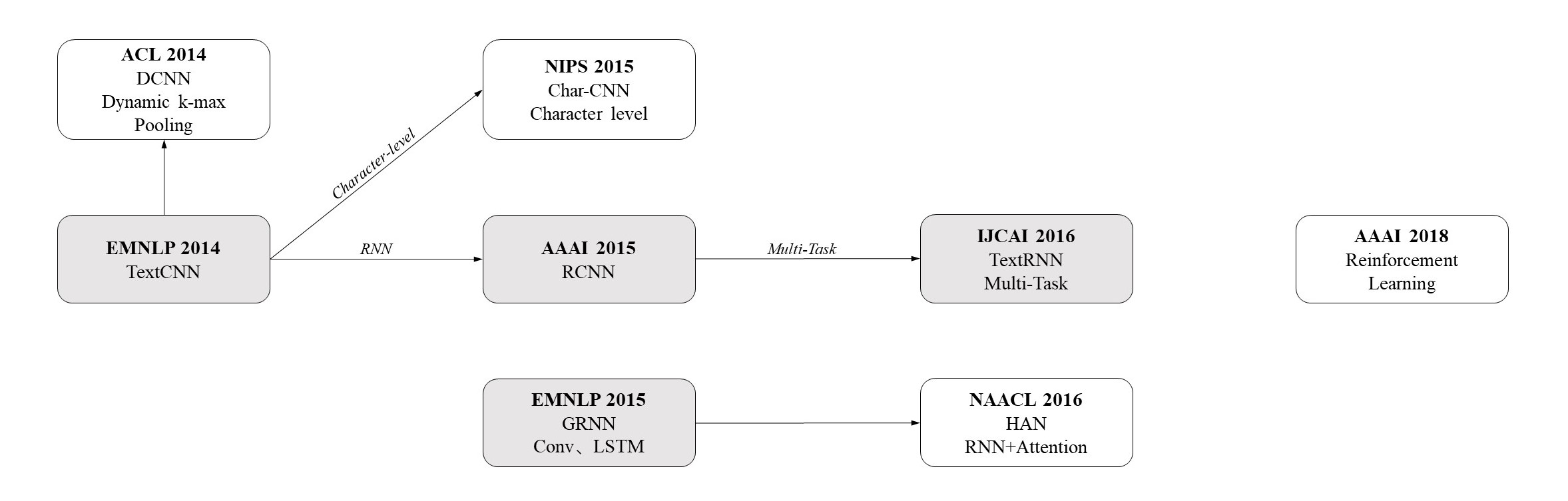
FastText
文章提出的方法类似于word2vec的cbow模型,并在此基础上加上bag of n-grams(考虑单词的顺序关系),下图是FastText文本分类的模型,$w$是语句中的词语,词语的向量相加求平均值作为文本表示然后做一个线性分类。
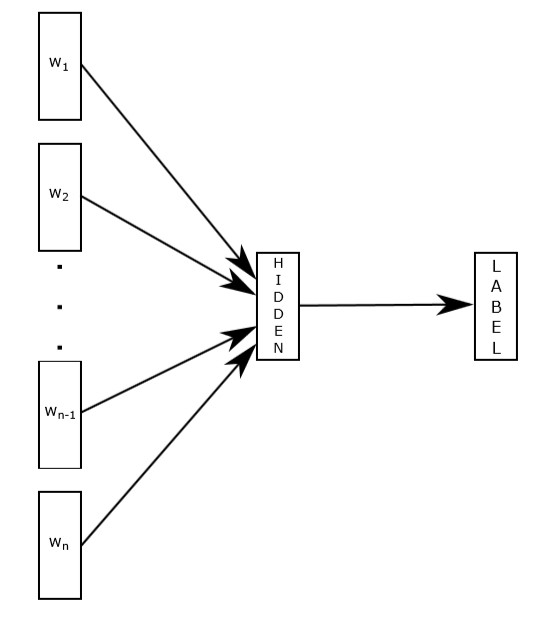
但与cbow不同的是,fasttext不是预测中心词,而是直接预测标签。模型以语句中的词语作为输入,输出语句属于各类别上的概率。
模型比较简单,训练速度很快,但是准确率不高。
TextCNN2014
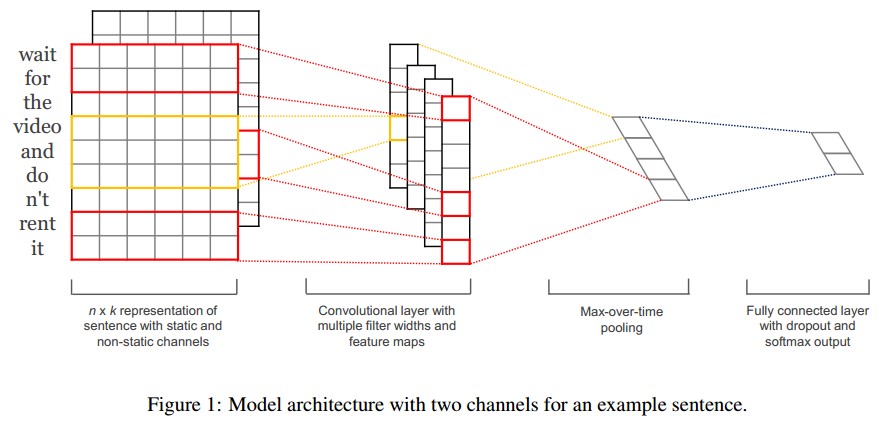
输入层将一个句子所有单词的词向量拼接成一个矩阵,每一行代表一个词。图中有两个channels,原文中用的是static和non-static,即使用的词向量是否随着训练发生变化;也可以使用不同的词向量方法生成的词向量作为不同channel。对于未登录词的向量,使用0或随机正数来填充。
卷积层的每个卷积核的大小为$filter-size\times embedding-size$。$filter-size$代表卷积核纵向上包含的单词个数,即认为相邻几个词之间有词序关系,代码里使用的是[3,4,5]。$embedding-size$就是词向量的维度。每个卷积核计算完成之后我们就得到了1个列向量,代表着该卷积核从句子中提取出来的特征。
池化层使用Max-over-time Pooling的方法。这种方法就是简单地从之前的Feature Map中提出最大的值(文中解释最大值代表着最重要的信号)。可以看出,这种Pooling方式可以解决可变长度的句子输入问题(因为不管Feature Map中有多少个值,只需要提取其中的最大值)。最终池化层的输出为各个Feature Map的最大值,即一个一维的向量。
全连接层,为了将pooling层输出的向量转化为我们想要的预测结果,加上一个softmax层。文中还提到了过拟合的问题,在倒数第二层的全连接部分上使用Dropout技术,即对全连接层上的权值参数给予L2正则化的限制。这样做的好处是防止隐藏层单元自适应(或者对称),从而减轻过拟合的程度。
本文使用的词向量是CBOW在Google News上的训练结果。
RCNN
分析了Recursive Neural Network、RNN、CNN做文本分类的优缺点:
Recursive Neural Network效果完全依赖于文本树的构建,并且构建文本树所需的时间是$ O\left( n^2 \right) $ 。并且两个句子的关系也不能通过一颗树表现出来。因此不适合于长句子或者文本。
RNN是有偏的模型,后面的词比前面的词更重要。
CNN卷积核的尺寸难以设置。如果选小了容易造成信息的丢失;如果选大了,会造成巨大的参数空间。
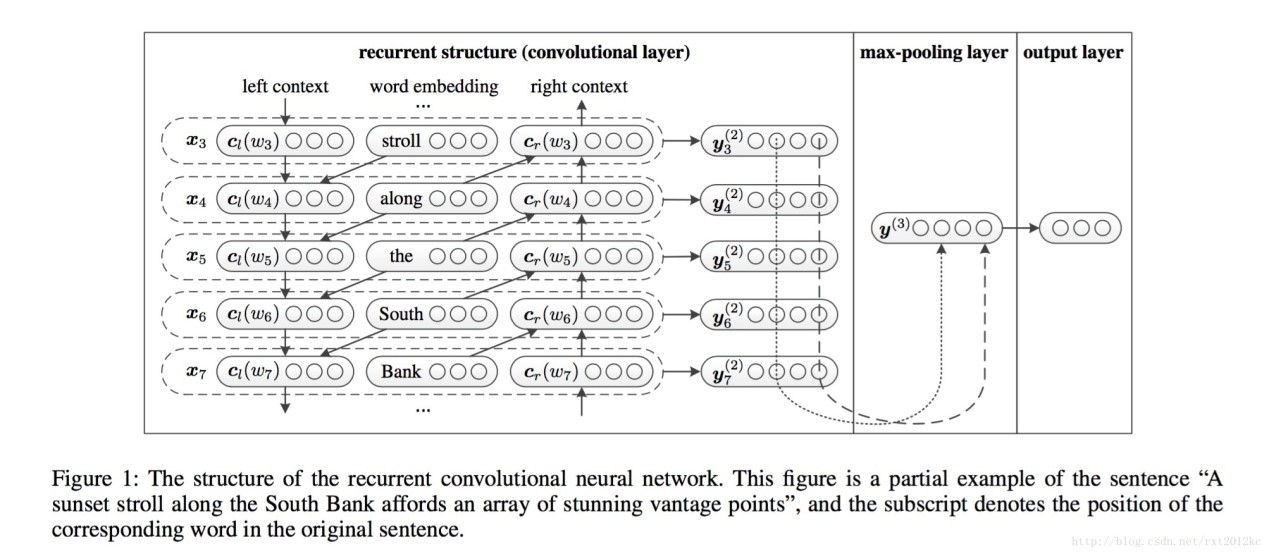
卷积层是一个BiRNN(双向LSTM),通过正向和反向循环来构建一个单词的上文和下文,如下式:
得到上下文表示后,拼接表示当前词:
使用$tanh$函数激活得到:
池化层使用最大池化,使用所有单词在每个维度上的最大值表示文本的信息。最后输出层使用softmax得到分类结果。
本文使用的词向量是使用Skip-gram训练的中英文Wikipedia。
TextRNN
传统的RNN(LSTM)结构:
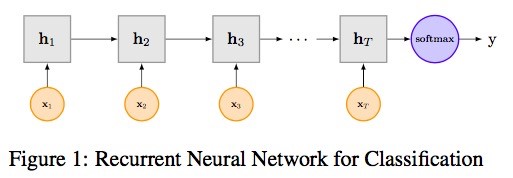
下面的公式为LSTM中各门的公式:
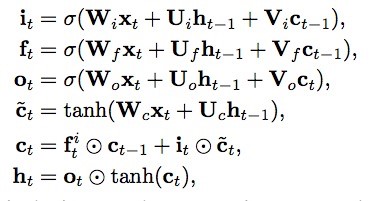
文章《Recurrent Neural Network for Text Classification with Multi-Task Learning》中介绍了RNN用于文本分类的模型设计,主要提出了以下三种模型:
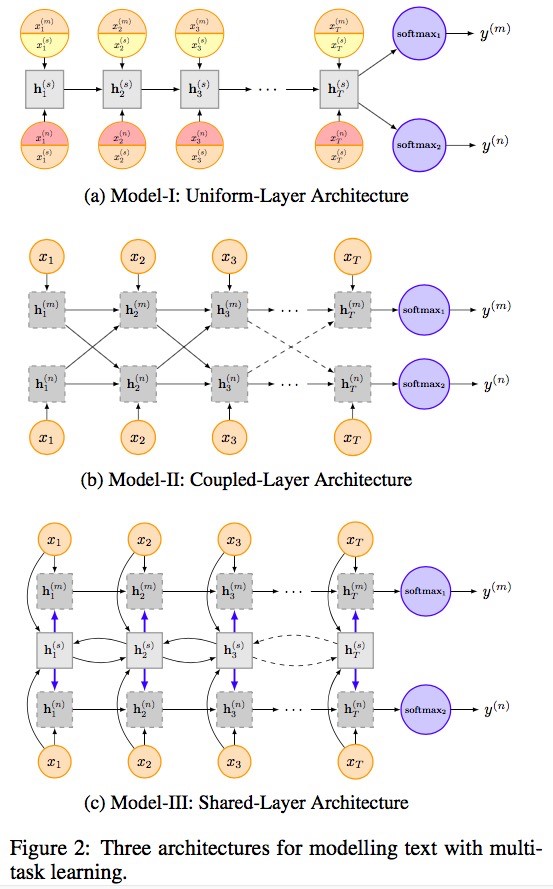
模型(a)中多任务共享LSTM结构以及公有的词向量;针对于任务$m$,输入$ \hat{x}_t $ 为:
其中,$ x{t}^{\left( m \right)} $ ,$ x{t}^{\left( s \right)} $ 分别表示任务私有的词向量和公有的词向量。最后一个时刻的hidden state则作为输入传入softmax。
模型(b)每个任务具有自己独立的LSTM层,但是每一时刻所有任务的hidden state则会和下一时刻的character一起作为输入,最后一个时刻的hidden state进行分类。作者修改了候选状态的计算公式:
模型(c)除了一个共享的BI-LSTM层用于获取共享信息,每个任务有自己独立的LSTM层,LSTM的输入包括每一时刻的character和BI-LSTM的hidden state,同模型2一样,作者修改了候选状态的计算公式:
本文使用的词向量是使用Word2Vec训练的Wikipedia语料。
CharCNN
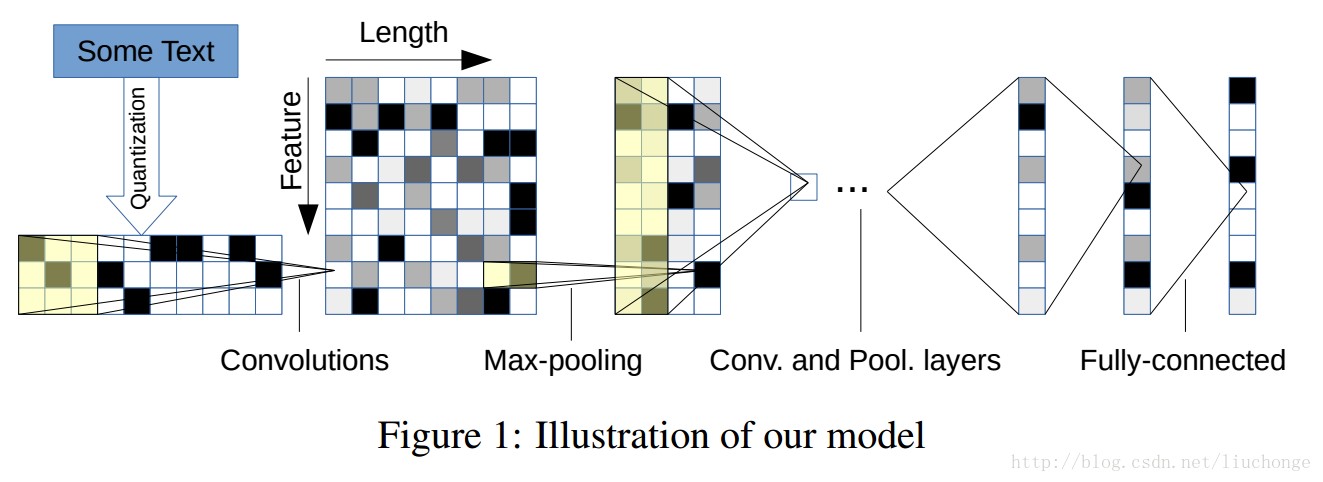
首先对文本编码,使用的字母表共有69个字符,对其使用one-hot编码,外加一个全零向量(用于处理不在该字符表中的字符),所以共70个。经过6个卷积层和3个全连接层得到输出。
优点是是不需要使用预训练好的词向量和语法句法结构等信息,并且可以很容易的推广到所有语言。针对于汉语,作者使用拼音代替汉字实现的编码。
对于几百上千等小规模数据集,可以优先考虑传统方法,对于百万规模的数据集,CharCNN表现不错。CharCNN适用于用户生成数据(user-generated data)(如拼写错误,表情符号等)。
GRNN(Conv、LSTM)
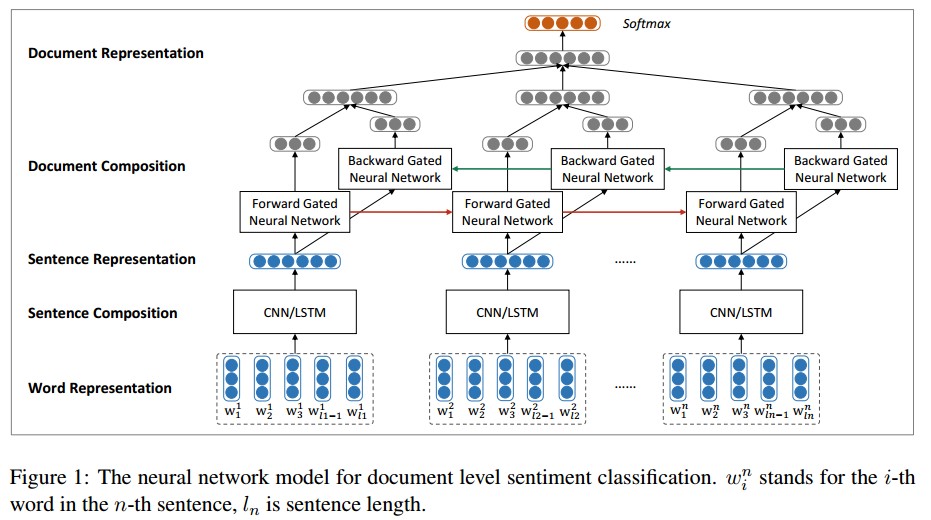
首先使用CNN/LSTM来建模句子表示,接下来使用双向GRU模型对句子表示进行编码得到文档表示,得到的文档表示用于Softmax情感分类。
在上图中,底层的词向量是由word2vec预训练得到。使用CNN/LSTM学习得到句子的表示,这里会把变长的句子表示表示成相同维度的向量。卷积模型如下:
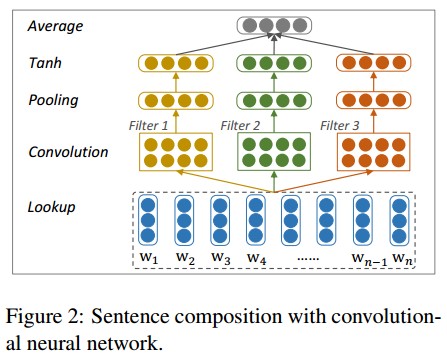
filter的宽度分别取1,2,3来编码unigrams,bigrams和trigrams的语义信息。最后使用一个Average层捕获全局信息并转化为输出向量。
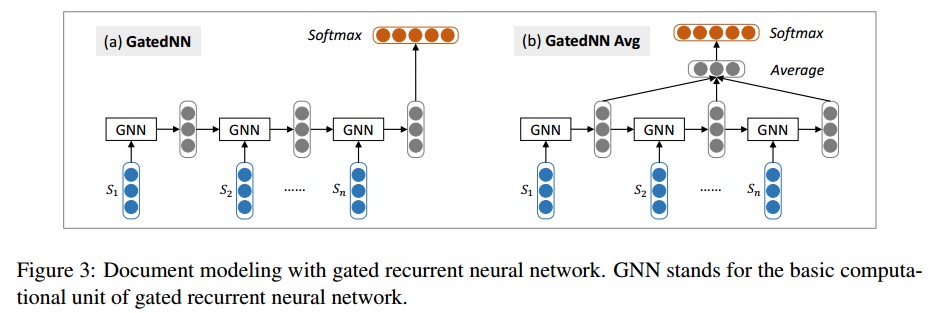
使用GRU模型,输入是变长的句子向量,输出固定长度的文本向量,这里会对最后每个单元的输出向量进行取平均操作
HAN(RNN+Attention)
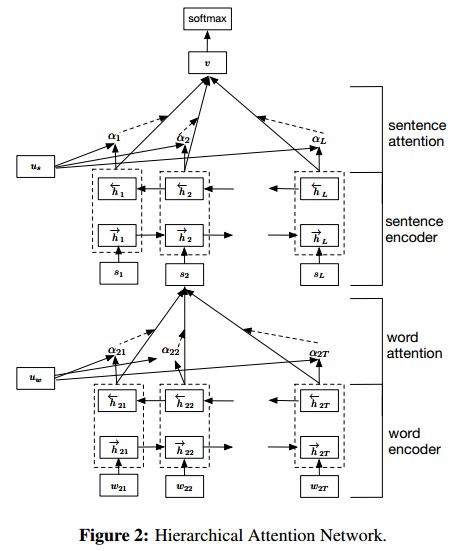
一个句子中每个单词的重要性不同。一篇文档中每个句子的重要性也不同。因此本文主要思想是,首先考虑文档的分层结构:单词构成句子,句子构成文档,所以建模时也分这两部分进行。其次,不同的单词和句子具有不同的信息量,不能单纯的统一对待所以引入Attention机制。而且引入Attention机制除了提高模型的精确度之外还可以进行单词、句子重要性的分析和可视化,让我们对文本分类的内部有一定了解。模型主要可以分为四个部分,如上图所示:
Word encoder和sentence encoder都是双向GRU,公式如下:
Word encoder中公式如下:
Word attention中公式如下:
Sentence encoder中公式如下:
Sentence attention中公式如下:
每个词语对应的hidden vector的输出经过变换(转置和$tanh$)之后和$u_w$ 相互作用(点积),结果就是每个词语的权重。加权以后就可以产生整个sentence的表示。从高一级的层面来看(hierarchical的由来),每个document有$L$个句子组成,那么这$L$个句子就可以连接成另一个sequence model, 同样是双向GRU,同样的对输出层进行变换后和 相互作用,产生每个句子的权重,加权以后我们就产生了对整个document的表示。最后用softmax就可以产生对分类的预测。
Reinforcement Learning
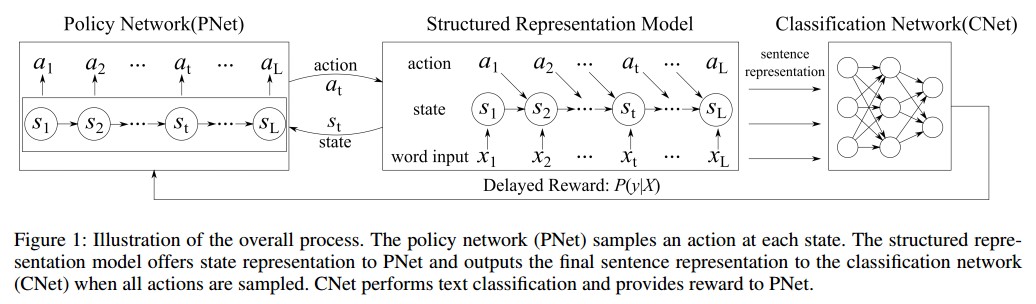
表征学习是自然语言处理中的一个基本问题。文章《Learning Structured Representation for Text Classification via Reinforcement Learning》研究如何学习文本分类的结构化表示。与大多数既不使用结构也不依赖于预定义结构的现有表示模型不同,作者提出了一种强化学习(RL)方法,通过自动地优化结构来学习句子表示。
作者在文章中提出两种结构表示模型(模型第二部分):Information Distilled LSTM (ID-LSTM) 和 Hierarchically Structured LSTM (HS-LSTM)。其中 ID-LSTM 只选择重要的任务相关的单词,HS-LSTM 则去发现句子中的短语结构。两种表示模型中的结构发现被表述为一个顺序决策问题,结构发现的当前决策影响随后的决策,这可以通过策略梯度 RL 来解决。
结果表明,这种方法可以通过识别重要的词或任务相关的结构而无需明确的结构注释来学习任务友好的表示,从而获得有竞争力的表现。