本文参考张俊林博士的《深度学习中的注意力机制》和苏剑林的《Attention is All You Need》浅读(简介+代码)》,简单总结一下 NLP 中用到的 attention 和 self-attention。
attention 的发展趋势
attention 机制的发展如下图所示: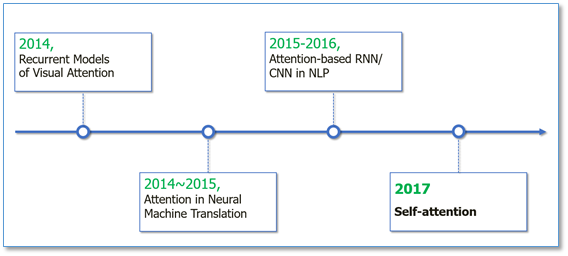
Attention机制最早是在视觉图像领域提出来的,但是真正火起来应该算是2014年google mind团队的论文《Recurrent Models of Visual Attention》,他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是第一个将attention机制应用到NLP领域中。接着attention机制被广泛应用在基于RNN/CNN等神经网络模型的各种NLP任务中。2017年,google机器翻译团队发表的《Attention is all you need》中大量使用了自注意力(self-attention)机制来学习文本表示。
NLP 中的序列编码
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。这样一来,每个句子都对应的是一个矩阵$X=(x_1,x_2,…,x_t)$,其中$x_i$都代表着第$i$个词的词向量(行向量),维度为$d$维,故$X\in\mathbb{R}^{n×d}$。这样的话,问题就变成了编码这些序列了。
RNN
第一个基本的思路是RNN层,RNN的方案很简单,递归式进行:
不管是已经被广泛使用的LSTM、GRU还是最近的SRU,都并未脱离这个递归框架。RNN结构本身比较简单,也很适合序列建模,但RNN的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。另外苏剑林提到:
RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
CNN
第二个思路是CNN层,其实CNN的方案也是很自然的,窗口式遍历,比如尺寸为3的卷积,就是
在FaceBook的论文中,纯粹使用卷积也完成了Seq2Seq的学习,是卷积的一个精致且极致的使用案例。CNN方便并行,而且容易捕捉到一些全局的结构信息。
attention
Google的大作提供了第三个思路:纯Attention!单靠注意力就可以!RNN要逐步递归才能获得全局信息,因此一般要双向RNN才比较好;CNN事实上只能获取局部信息,是通过层叠来增大感受野;attention的思路最为粗暴,它一步到位获取了全局信息!它的解决方案是:
其中$A$,$B$是另外一个序列(矩阵)。如果都取$A=B=X$,那么就称为Self-Attention,它的意思是直接将$x_t$与原来的每个词进行比较,最后算出$y_t$!
attention
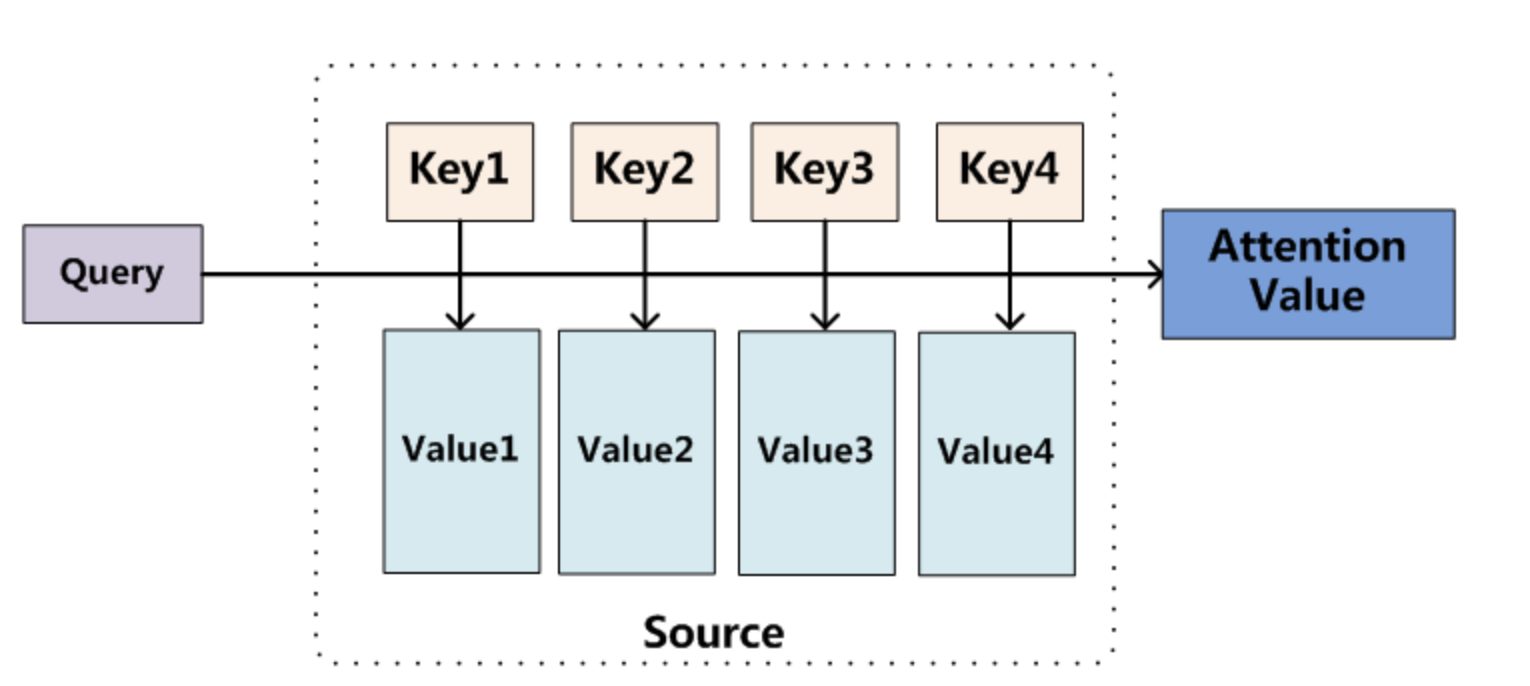
将Source中的构成元素想象成是由一系列的< Key,Value >数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
其中, $L_x=||Source||$代表Source的长度。在机器翻译中,Source中的Key和Value指向的是同一个东西(输入句子中每个单词对应的语义编码)。
attention计算过程
- 根据Query和Key计算两者的相似性或者相关性;
- 对第一阶段的原始分值进行归一化处理,得到权重系数;
- 根据权重系数对Value进行加权求和。
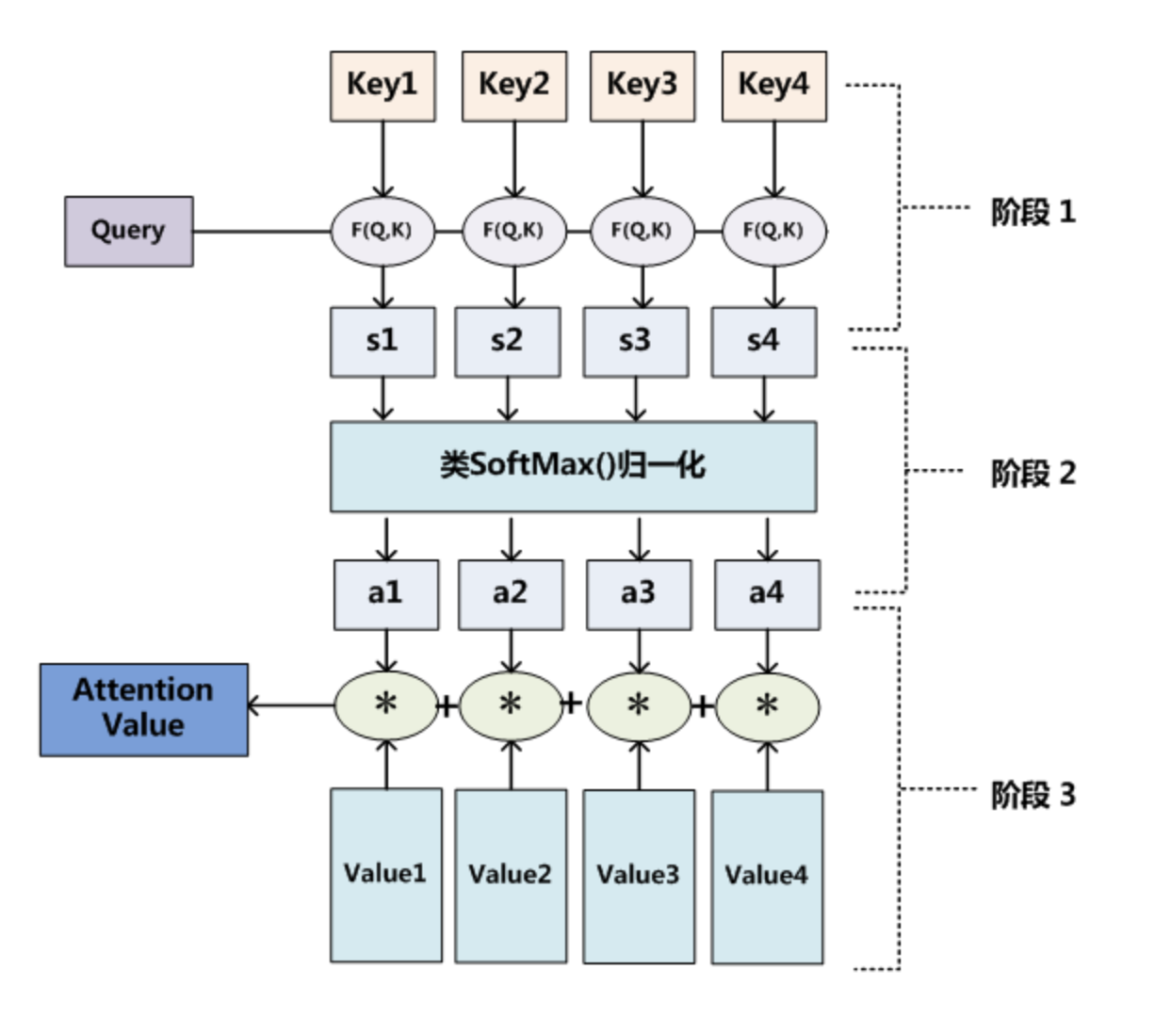
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个$Key_i$,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:
第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
第二阶段的计算结果$a_i$即为$Value_i$对应的权重系数,然后进行加权求和即可得到Attention数值:
self-attention
Google的论文模型的整体结构如下图,还是由编码器和解码器组成,在编码器的一个网络块中,由一个多头attention子层和一个前馈神经网络子层组成,整个编码器栈式搭建了N个块。类似于编码器,只是解码器的一个网络块中多了一个多头attention层。为了更好的优化深度网络,整个网络使用了残差连接和对层进行了规范化(Add&Norm)。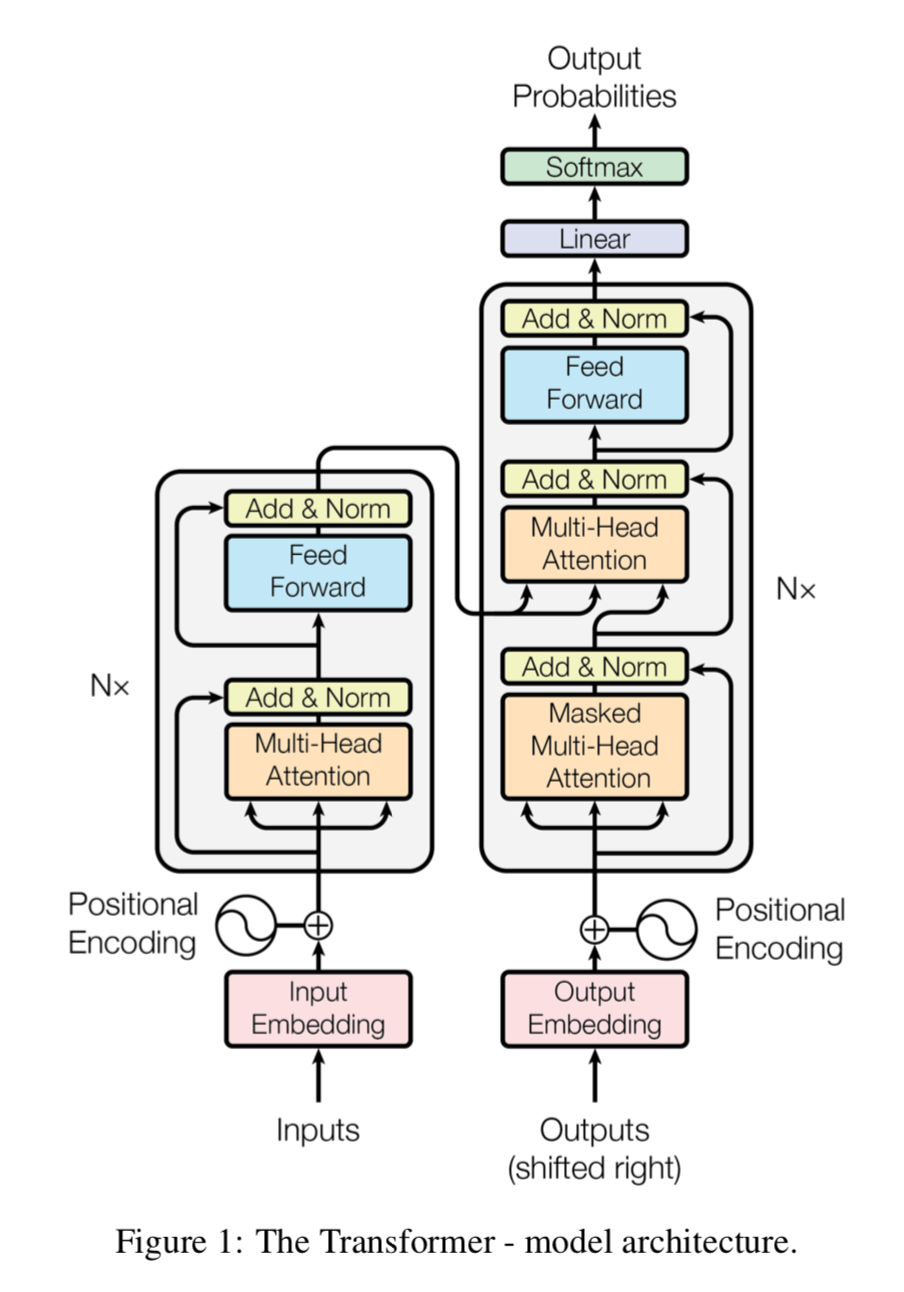
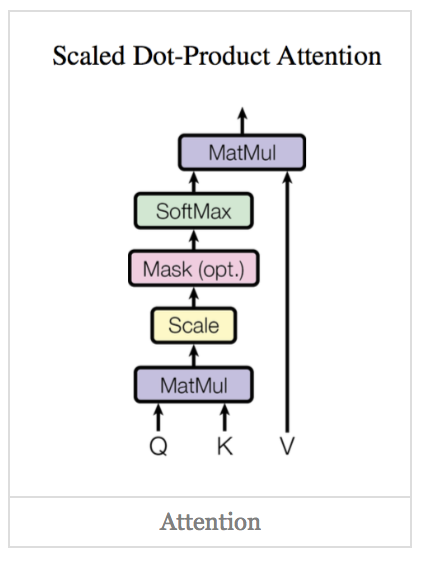
scaled dot-Product attention
对比我在前面背景知识里提到的attention的一般形式,其实scaled dot-Product attention就是我们常用的使用点积进行相似度计算的attention,只是多了一个$\sqrt{d_k}$,$\sqrt{d_k}$为$K$的维度,起到调节作用,使得内积不至于太大。
Multi-Head Attention
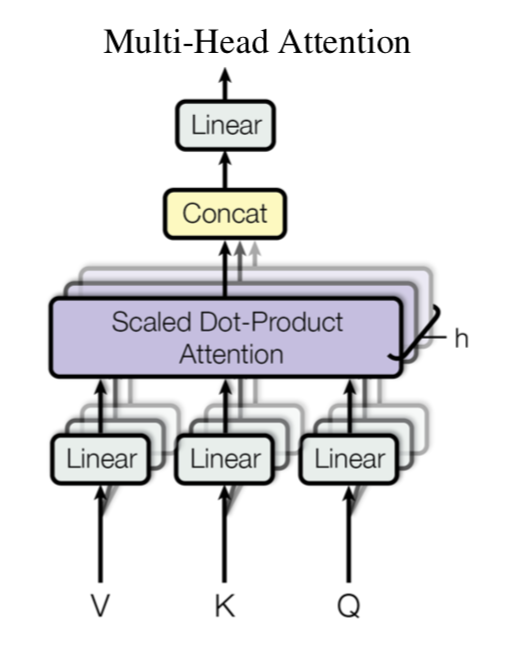
多头attention(Multi-head attention)结构如上图,Query,Key,Value首先经过一个线性变换,然后输入到scaled dot-Product attention,注意这里要做h次,其实也就是所谓的多头,每一次算一个头。而且每次Q,K,V进行线性变换的参数W是不一样的。
然后将h次的放缩点积attention结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。
可以看到,google提出来的多头attention的不同之处在于进行了h次计算而不仅仅算一次,论文中说到这样的好处是可以允许模型在不同的表示子空间里学习到相关的信息。这里的设计类似于 CNN 的多个卷积核。
Self Attention
所谓Self Attention,其实就是$Attention(X,X,X)$,$X$就是前面说的输入序列。也就是说,在序列内部做Attention,寻找序列内部的联系。更准确来说,Google所用的是Self Multi-Head Attention:
Position Embedding
但是这样的模型并不能捕捉序列的顺序!换句话说,如果将$K,V$按行打乱顺序(相当于句子中的词序打乱),那么Attention的结果还是一样的。这就表明了,到目前为止,Attention模型顶多是一个非常精妙的“词袋模型”而已。
于是Google再又提出了Position Embedding,也就是“位置向量”,将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了。
在以往的Position Embedding中,基本都是根据任务训练出来的向量。而Google直接给出了一个构造Position Embedding的公式:
将id为$p$的位置映射为一个$d_{pos}$维的位置向量,这个向量的第$i$个元素的数值就是$PE_i(p)$。
结合位置向量和词向量有几个可选方案,可以把它们拼接起来作为一个新向量,也可以把位置向量定义为跟词向量一样大小,然后两者加起来。FaceBook的论文和Google论文中用的都是后者。
代码实现
attention:
Keras:
https://github.com/fuliucansheng/360/blob/master/models/deepzoo.py
self-attention:
tf的实现:
https://github.com/bojone/attention/blob/master/attention_tf.py
Keras版:
https://github.com/bojone/attention/blob/master/attention_keras.py