CCF 大数据与计算智能大赛(BDCI)
【赛题四】360搜索-AlphaGo之后“人机大战”Round 2 ——机器写作与人类写作的巅峰对决
比赛时间2017.10-2017.12
赛事背景
如果说AlphaGo和人类棋手的对决拉响了“人机大战”的序曲,在人类更为通识的写作领域,即将上演更为精彩的机器写作和人类写作的对决。人类拥有数万年的书写历史,人类写作蕴藏无穷的信息、情感和思想。但随着深度学习、自然语言处理等人工智能技术发展,机器写作在语言组织、语法和逻辑处理方面几乎可以接近人类水平。360搜索智能写作助手也在此背景下应运而生。
本次CCF大数据和人工智能大赛上,360搜索智能写作助手(机器写作)和人类写作将狭路相逢,如何辨别出一篇文章是通过庞大数据算法训练出来的机器写作的,还是浸染漫长书写历史的人类创作的?我们拭目以待!
本次赛题任务:挑战者能够设计出优良的算法模型从海量的文章中区分出文章是机器写作还是人类写作。
解题思路
传统文本分类
文本分类问题算是自然语言处理领域中一个非常经典的问题,目前形成了一套经典算法,这个阶段的主要是人工特征工程+浅层分类模型。训练文本分类器过程见下图: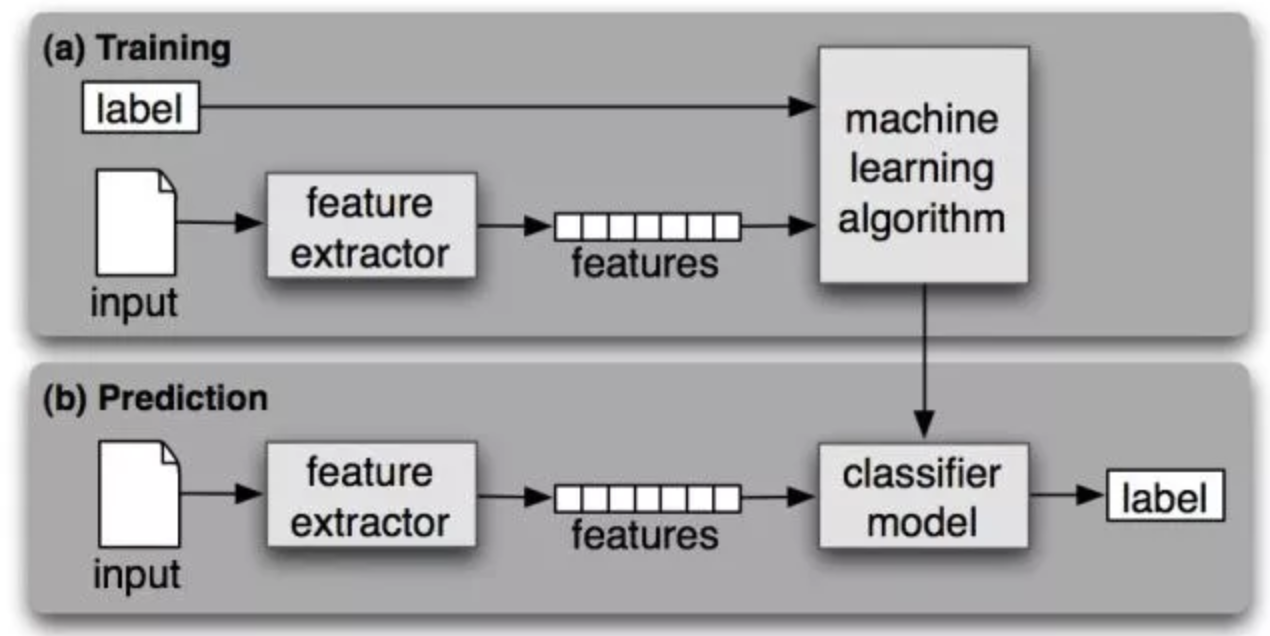
深度学习方法
CNN 方法
我们首先设计了基于词项和字符的卷积神经网络模型 (Char-CNN、Word-CNN、WordChar-CNN) 来提取局部感受野的特征。根据观察,词序级别的错误或颠倒是负样本中出现次数最多的问题,而卷积神经网络中的卷积+池化操作能够很好的捕获这种 N-Gram 的错误。Char-CNN 首先对单个字进行向量表示,随后输入 三通道的卷积神经网络通过池化层提取特征,最后进行二分类的 softmax 得到每一类的概率。Word-CNN 和 WordChar-CNN 的模型与 Char-CNN 类似,只是在输入数据上,Word-CNN 读取的是分词后的词向量表示而 WordChar-CNN 综合考虑了词项和字符的特征,相当于前两个模型的集成。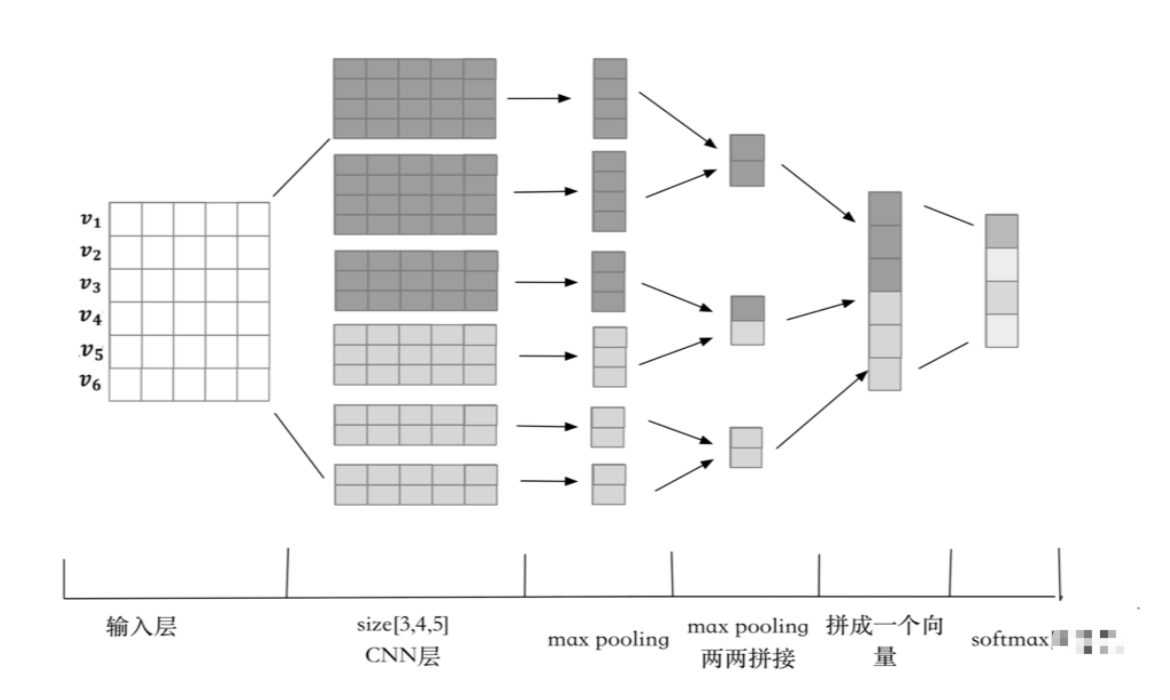
RNN + Attention方法
除了上述词序问题,负样本还有很多语句重复或语句不连贯的问题。而带有 Attention 机制的循环神经网络模型十分适合提取这样的特征,因此我们针对此类样本设计了加入注意力机 制的循环神经网络模型 (Word-HAN) 模型,首先对分词后的词项进行向量表示,随后通过双向 GRU 来提取句子每个时序的特征,使用 Attention 机制来提取更大视野窗又的不连贯特征以及缓解长距离依赖问题,这样就可以得到句子的向量表示,最后再使用相同的方法获得文章的向量表示并进行二分类操作。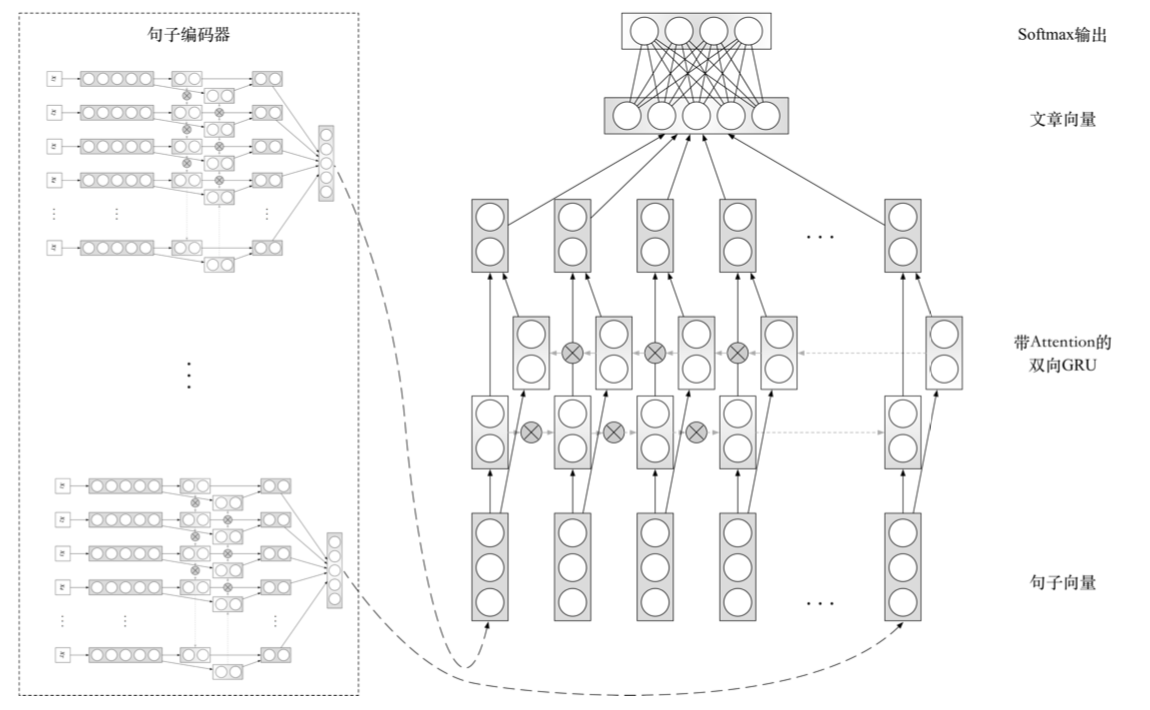
CNN + RNN + Attention 方法
我们还思考了如何在不过分牺牲训练时间的同时尽可能地提高循环神经网络的表现性能。我们认为,传统的 LSTM、GRU 模型对句子语义较为敏感,能够很好的保留句子的语义。但是对感知相邻句子之间的错误并不敏感,如果能让它结合卷积神经网络的优点,就可以增强模型的特征提取能力。基于这种想法,我们设计了 Word-HCNN 模型,结构如图所示。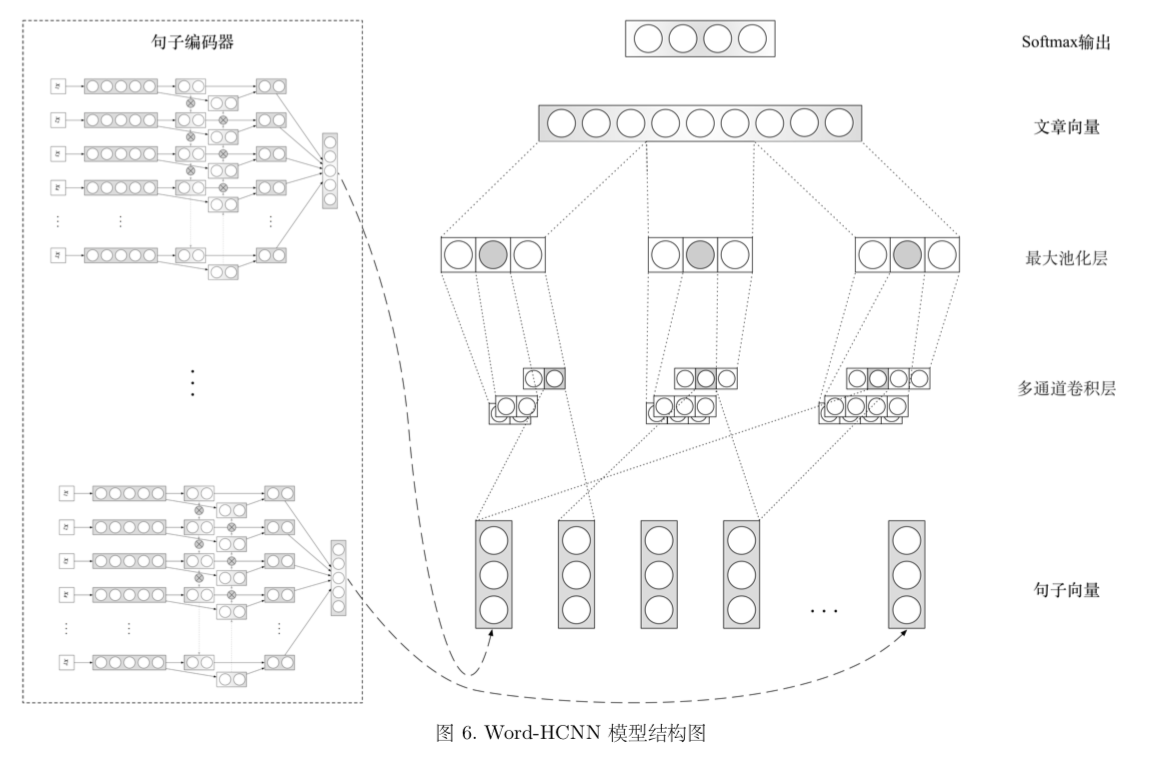
Word-HCNN 综合了 Word-HANN 的和 Word-CNN 的网络结构。首先通过双向 GRU+Attention 的方法将每个句子表示成为向量,再通过多通道卷积提取相邻句子之间特征,这是句子级别的”N-Gram”,模型的输出层依旧是一个 2 分类的 softmax。
样本数据分析
因为分类问题中类别平衡与否对最终的分类结果会产生很大的影响,所以我们首先统计了类别分布情况。两类样本大致平衡。
与此同时,我们还对文章长度分布进行了统计,总体来看,几乎所有文章的长度都在 1500 个词以内,这符合我们的正常认知。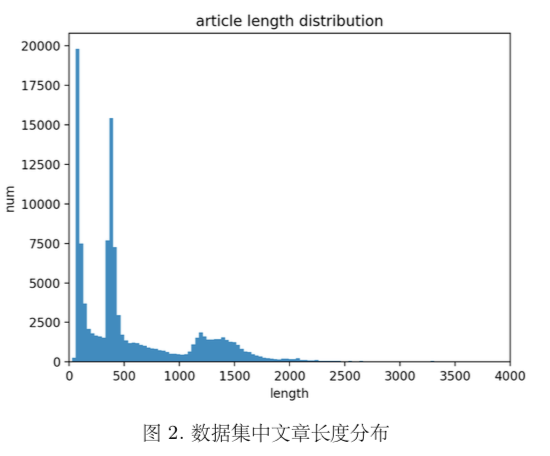
数据预处理与模型初始参数
考虑到卷积神经网络只能处理固定维度的输入数据,所以我们对于长度为 $n$ 的文章,首先对文章进行截断或者补齐到固定长度 $T$,如果 $n > T$,则只保留前 $T$ 个 单词,如果 $n < T$,则在文章末尾添加 padding 来补齐长度。预处理之后,每篇文章都包含 T 个词。
尽管 RNN 能够处理变长的时序数据,但是考虑到矩阵操作的便利,我们依然需要固定输入的维度对数据进行预处理,与卷积神经网络不同的是,循环神经网络是以句子作为处理单元,而不是把文章中的所有词都拼在一起。对于包含 $s$ 个句子的文章,首先进行句子级别的截断或者补齐到固定数目 $S$ ,如果 $s > S$ ,则只保留前 $S$ 个句子,如果 s < S,则添加 padding 补齐句子数目。同样的操作也作用于每个句子,对于长度为 $n$ 的句子,首先对句子进行截断或者补齐到固定长度 $T$ , 如果$n>T$,则只保留前 $T$ 个单词,如果$n<T$,则在句子末尾添加 padding 补齐长度。预处理之后,每篇文章都被包含 $S$ 个句子,每个句子都包含 $T$ 个词。
将数据集按照 6:2:2 的比例拆分成训练集,验证集和测试集三部分。文章截断 补齐句子数为 45,句子截断补齐词个数为 48,分词工具使用 jieba,输入层使用 wiki 语料通过 word2vec 预训练得到的 100 维向量,只保留频率最高的前 10000 个单词,其他单词均映射为