本文主要基于 Hyperledger fabric 的官方文档和网上较新的博客,在一台MacOS上实现了Building Your First Network。
Hyperledger fabric v1.0.0 环境部署过程
本文主要基于 Hyperledger fabric 的官方文档来搭建其实验环境,但官方文档对于很多步骤都有省略,结合网上比较新的博客,在一台 Ubuntu 14.04 机器(没用通过测试,换成了16.04的虚拟机)上来安装部署 fabric 的环境。
2018.08.22收获与总结
今天处理了一下THUC的新闻数据集,具体代码在下面。
收获
sklearn里的shuffle可以将数据打乱,我在之前处理南开数据集的时候忽视了这一点。同样,pandas中的sample()也是同样的作用,numpy库中的方法不推荐,会导致内存溢出。
总结
离开实验室的时候跑了TextCNN的模型,结果到家看了一下结果,从第九个epoch开始准确率都为1(一共15个epochs)。一开始我纳闷为啥准确率这么高,因为在复旦数据集上也就0.86左右的准确率。后来看了一下下面的代码。最后两行是我生成训练集和测试集的方法,仔细看知道了测试集就是训练集的一个子集!怪不得准确率这么高,因为已经告诉你label了啊!明天重新生成一下训练集和测试集。
scipy.stats.spearmanr用法
计算Spearman秩相关系数和P值(非相关性检验)。
在计算word similarity时用到的。具体用法是数据集中每行有一对词和人工标注的相关性,如(李白 诗 9.2)。程序先从词向量中读取两个词的向量,求得两个向量的余弦相似性,再用spearmanr求得相关系数和P值。最后的实验分析用的是相关系数。
keras中的embedding层
keras中的Embedding层
将索引映射为固定维度的稠密向量,如[[4],[20]]->[[0.25,0.1],[0.6,-0.2]]。
Embedding层只能作为模型的第一层。
如何使用
- 从头训练
就像word2vec一样, 这一层是可学习的, 用随机数initialize , 通过BP去调整. - pre-trained + fine tuning
用其他网络(如 word2vec) 训练好的现成的词向量, 作为初始化参数, 然后继续学习. - pre-trained + static
用其他网络(如 word2vec) 训练好的现成的词向量, 作为初始化参数, 并且这些参数保持固定, 不参与网络的学习.参数说明
1
keras.layers.embeddings.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)
input_dim:大或等于0的整数,字典长度(词汇量),即输入数据最大下标+1
output_dim:大于0的整数,代表词向量的维度
embeddings_initializer: 初始化方法
embeddings_regularizer: 嵌入矩阵的正则项,为Regularizer对象
embeddings_constraint: 嵌入矩阵的约束项,为Constraints对象
mask_zero:布尔值,确定是否将输入中的‘0’看作是应该被忽略的‘填充’(padding)值,该参数在使用递归层处理变长输入时有用。设置为True的话,模型中后续的层必须都支持masking,否则会抛出异常。如果该值为True,则下标0在字典中不可用,input_dim应设置为$|vocabulary| + 1$。
input_length:当输入序列的长度固定时,该值为其长度。如果要在该层后接Flatten层,然后接Dense层,则必须指定该参数,否则Dense层的输出维度无法自动推断。
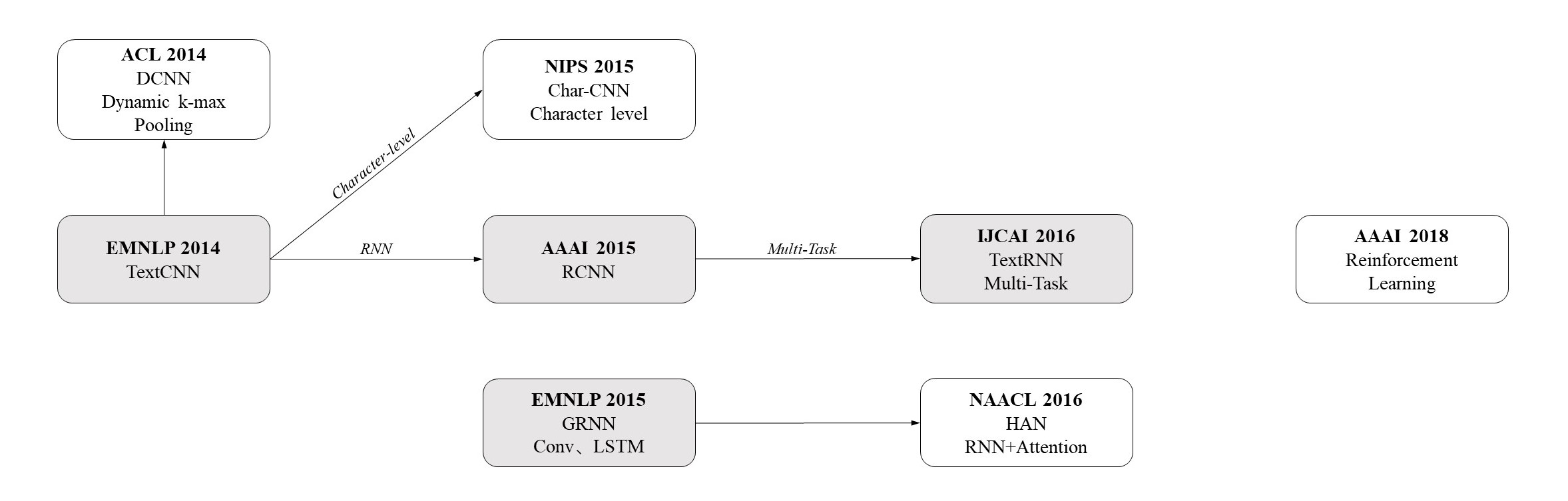
词向量综述
本文总结了词向量的多种表示方法,主要为word2vec基础上的多种模型,侧重于中文词向量模型。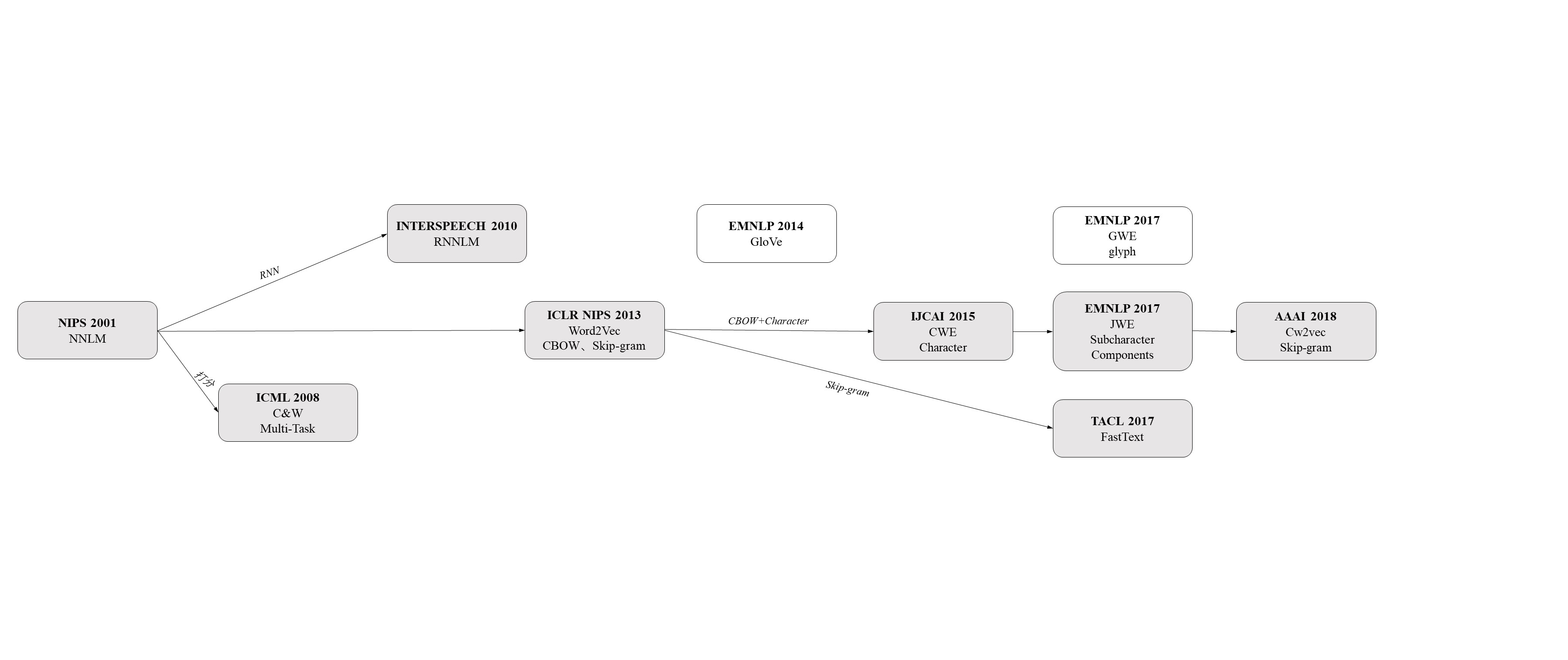
2018年7月23日更新,在NLP课上宗成庆老师在讲词向量时提到,除了基于文本的词汇语义表示模型,还有基于图像、语音、多模态信息学习词汇语义表示等,这一些有空再补充。
GWE:Learning Chinese Word Representations From Glyphs Of Characters读书笔记
本文总结了论文GWE:Learning Chinese Word Representations From Glyphs Of Characters中的核心思想。
JWE:Joint Embeddings of Chinese Words,Characters,and Fine-grained Subcharacter Components
本文总结了论文JWE:Joint Embeddings of Chinese Words, Characters, and Fine-grained Subcharacter Components中的核心思想。