梯度提升决策树GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就和SVM一起被认为是泛化能力较强的算法。
GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类。
回归树Regression Decision Tree
回归树总体流程类似于分类树,区别在于,回归树的每一个节点都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化平方误差。也就是被预测出错的人数越多,错的越离谱,平方误差就越大,通过最小化平方误差能够找到最可靠的分枝依据。分枝直到每个叶子节点上人的年龄都唯一或者达到预设的终止条件(如叶子个数上限),若最终叶子节点上人的年龄不唯一,则以该节点上所有人的平均年龄做为该叶子节点的预测年龄。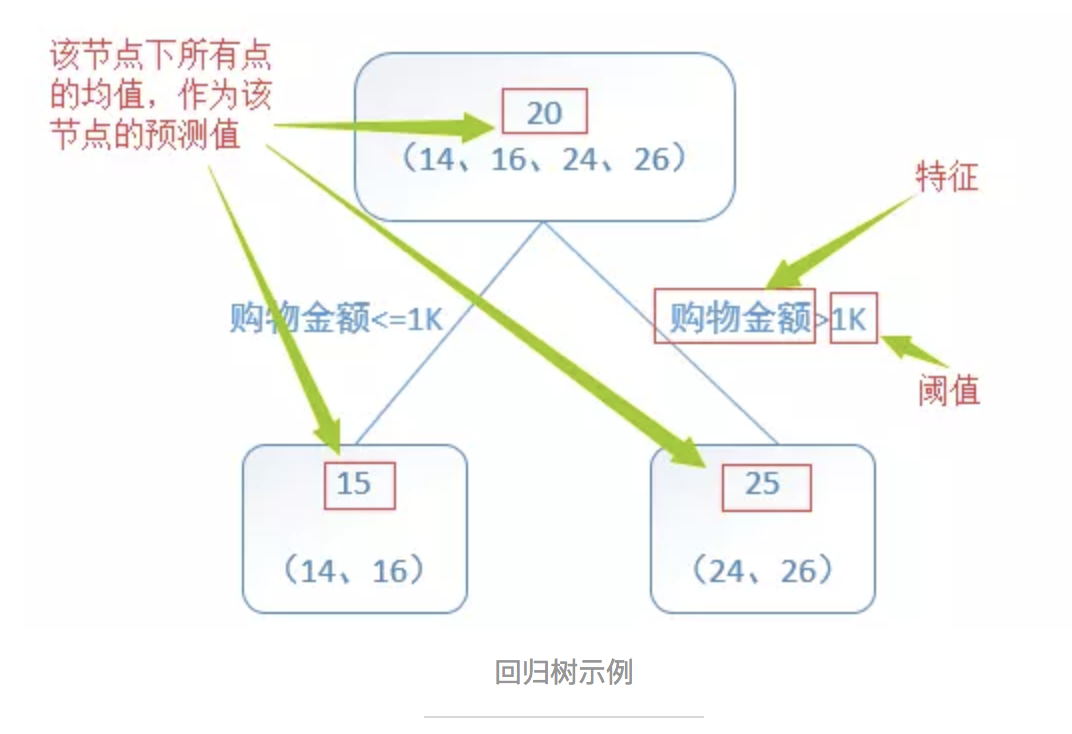
回归树算法如下图(截图来自《统计学习方法》5.5.1 CART生成):
提升树Boosting Decision Tree
提升树是迭代多棵回归树来共同决策。当采用平方误差损失函数时,每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树,残差的意义如公式:残差 = 真实值 - 预测值 。提升树即是整个迭代过程生成的回归树的累加。
举个例子,较直观地展现出多棵决策树线性求和过程以及残差的意义。
训练一个提升树模型来预测年龄:
训练集是4个人,A,B,C,D年龄分别是14,16,24,26。样本中有购物金额、上网时长、经常到百度知道提问等特征。提升树的过程如下: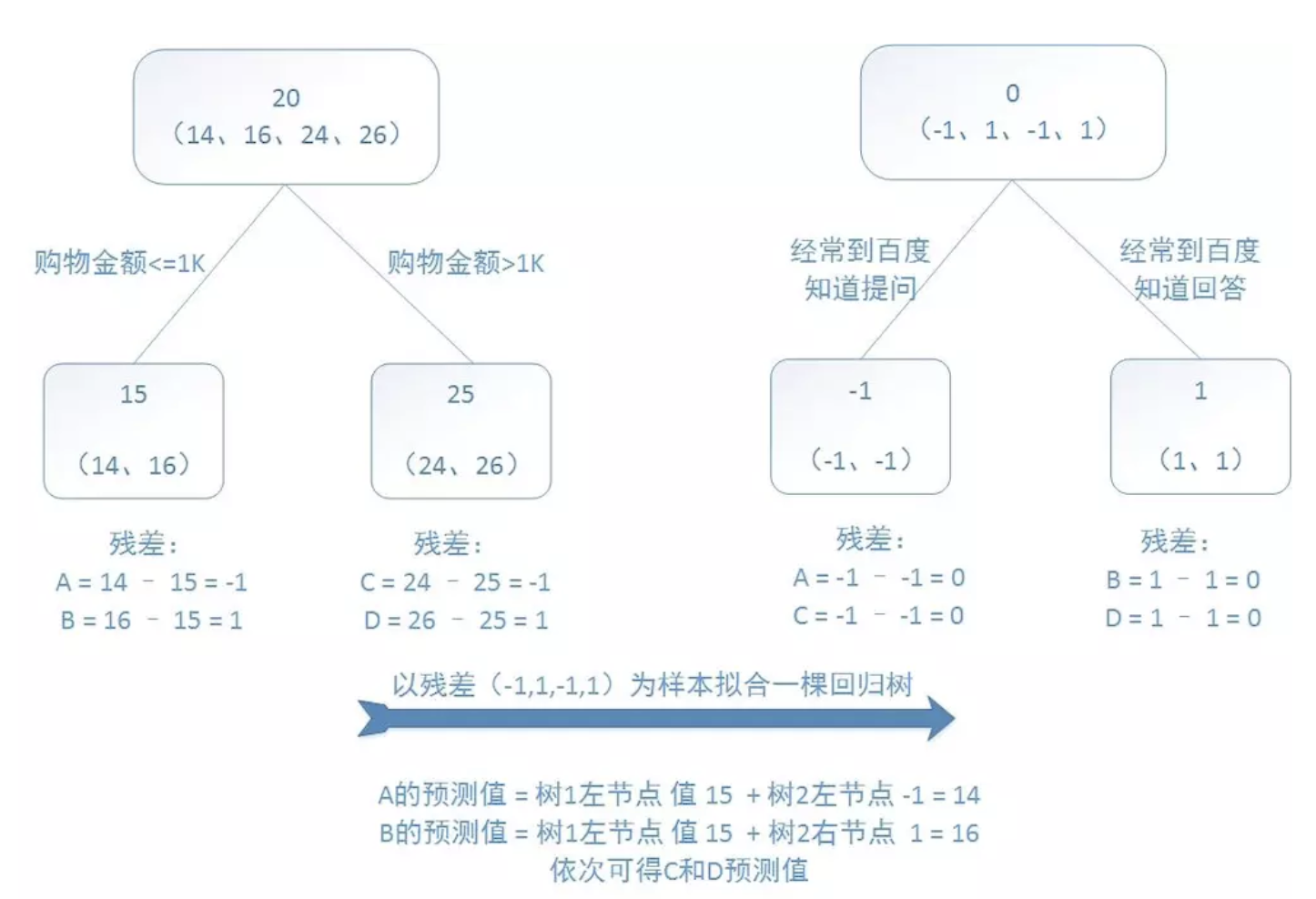
该例子很直观的能看到,预测值等于所有树值得累加,如A的预测值 = 树1左节点 值 15 + 树2左节点 -1 = 14。
因此,给定当前模型 $f_{m-1}(x)$,只需要简单的拟合当前模型的残差。现将回归问题的提升树算法叙述如下
梯度提升决策树Gradient Boosting Decision Tree
提升树利用加法模型和前向分步算法实现学习的优化过程。当损失函数是平方损失和指数损失函数时,每一步的优化很简单,如平方损失函数学习残差回归树。
但对于一般的损失函数,往往每一步优化没那么容易,如上图中的绝对值损失函数和Huber损失函数。针对这一问题,Freidman提出了梯度提升算法:利用最速下降的近似方法,即利用损失函数的负梯度在当前模型的值,作为回归问题中提升树算法的残差的近似值,拟合一个回归树。
算法步骤解释:
参考:https://www.cnblogs.com/pinard/p/6140514.html
1、初始化,估计使损失函数极小化的常数值,它是只有一个根节点的树。
2、
(a)计算损失函数的负梯度在当前模型的值,将它作为残差的估计,第t轮的第i个样本的损失函数的负梯度表示为$r{ti} = -\bigg[\frac{\partial L(y_i, f(x_i)))}{\partial f(x_i)}\bigg]{f(x) = f{t-1}\;\; (x)}$
(b)利用$(x_i,r{ti})\;\; (i=1,2,..m)$,我们可以拟合一颗CART回归树,得到了第t颗回归树,其对应的叶节点区域$R{tj}, j =1,2,…, J$。其中J为叶子节点的个数。
(c)利用线性搜索估计叶节点区域的值,使损失函数极小化$$c{tj} = \underbrace{arg\; min}{c}\sum\limits{xi \in R{tj}} L(yi,f{t-1}(xi) +c)h_t(x) = \sum\limits{j=1}^{J}c{tj}I(x \in R{tj})$$
3、得到输出的最终模型 f(x)